227 Evidence-Based Critical Care
The practice of critical care, like all fields of medicine, is changing constantly, and the pace of change is ever increasing. Among the many forces for change, the rapid increase in information is one of the most important. Although the majority of practitioners do not engage in research themselves, they are consumers of research information and must therefore understand how research is conducted to apply this information to their patients. Fellowship programs in critical care medicine emphasize education in this area to varying degrees. The traditional approach has been to require fellows to actively participate in a research project, either clinical or basic science. However, there has also been a growing interest in instructing fellows in the methods of clinical epidemiology.1 The practical application of clinical epidemiology is evidence-based medicine (EBM), which Sackett defines as “the conscientious and judicious use of current best evidence in making decisions about the care of individual patients.”2 The clinical practice of EBM involves integrating this evidence with individual physician expertise and patient preferences so informed, thoughtful medical decisions are made.3 In this chapter we present the methodology of EBM and its application in critical care medicine.
 Asking a Question
Asking a Question
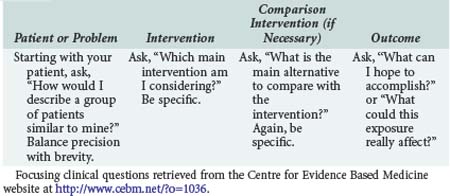
The first step in practicing EBM is asking a well-constructed clinical question. To benefit the patient and aid the clinician, clinical questions must be both directly relevant to patients’ problems and constructed in a way that guides an efficient literature search to relevant and precise answers. The Centre for Evidence Based Medicine (CEBM) in Oxford, England, provides an excellent description of the four essential elements of an EBM question, summarized in Table 227-1.
 Types of Evidence
Types of Evidence
Primary Research
Randomized Clinical Trials
Randomized clinical trials, also referred to as experimental or interventional studies, are the cornerstones of medical evidence. Physicians place considerable faith in the results of randomized control trials.4,5 This faith is placed with good reason, as randomization remains perhaps the best solution to avoid misinterpreting the effect of a therapy in the presence of confounding variables.6 When participants are randomly allocated to groups, factors other than the variable of interest (e.g., a new therapy for sepsis) that are likely to affect the outcome of interest are usually distributed equally to both groups. For example, with randomization, the number of patients with underlying comorbidity that may adversely affect outcome should be similar in each study arm, presuming sample size is appropriate. A special advantage of randomization is that this equal distribution will occur for all variables (excluding the intervention) whether these variables are identified by the researcher or not, thus maximizing the ability to determine the effect of the intervention.
However, RCTs are expensive, difficult, and sometimes unethical to conduct, with the consequence that less than 20% of clinical practice is based on the results of RCTs.7 Moreover, many important questions such as determining the optimal timing of a new therapy or determining the effects of health care practices cannot practically be studied by RCTs.
Observational Studies
Observational outcomes studies are very powerful tools for addressing many questions that RCTs cannot address, including measuring the effect of harmful substances (e.g., smoking and other carcinogens), organizational structures (e.g., payer status, open versus closed ICUs), or geography (e.g., rural versus urban access to health care). Because of their cost and the regulatory demands on drug and device manufacturers, RCTs are frequently designed as efficacy studies in highly defined patient populations with experienced providers and therefore provide little evidence about effectiveness in the “real” world.8 Alternatively, observational studies can generate hypotheses about the effectiveness of treatments that can be tested using other research methods.8 Investigators have also explored the effects of different therapies that are already accepted but used variably in clinical practice.9
However, observational studies have several significant limitations. First, the data source must be considered. Observational outcomes studies are often performed on large data sets wherein the data were collected for purposes other than research. This can lead to error owing to either a lack of pertinent information or bias in the information recorded.10 Second, one must consider how the authors attempt to control for confounding. The measured effect size of a variable on outcome (e.g., the effect of the pulmonary artery catheter on mortality rate) can be confounded by the distribution of other known and unknown variables. More specifically, case-control studies are subject to recall and selection bias, and the selection of an appropriate control group can be difficult. Cross-sectional studies can only establish association (at most), not causality, and are also subject to recall bias. Cohort studies have a number of limitations, including difficulty in finding appropriate controls and difficulty determining whether the exposure being studied is linked to a hidden confounder, and the requirement of large sample size or long follow-up to sufficiently answer a research question can be timely and expensive.
Single-Study Results—Critically Appraised Topics
Determining which studies provide information useful in the care of patients is largely a question of deciding whether a study is valid and, if so, can its results be applied to the patients in question. One format for appraising individual studies is the critically appraised topic (CAT) format that has been popularized as part of EBM. The purpose of the CAT is to evaluate a given study or set of studies using a standardized approach. Studies that address diagnosis, prognosis, etiology, therapy, and cost-effectiveness all have a separate CAT format.3 An example is shown in Box 227-1 for studies that address therapy. The CAT format for studies on therapy asks several questions intended to address the issues of validity and clinical utility. Studies that fail to achieve these measures are not generally useful, although studies do not necessarily have to fulfill every criterion, depending on the nature of the topic. For example, a study that examined the effect of walking once a day for the prevention of stroke would not be expected to include a detailed examination of side effects or a cost-effectiveness analysis. However, a study comparing streptokinase to placebo for treatment of stroke would likely be required to include a detailed examination of side effects and a cost-effectiveness analysis because of the excessive risks and costs associated with such therapy. Similarly, blinding may not always be possible, and the effects of the investigators being unblinded can be minimized by separating them from the clinicians making the treatment decisions or by establishing standard treatment protocols that are applied equally to both the study and control groups. Alternatively, a study would be “fatally flawed” if it failed in terms of randomization or was not analyzed as “intention to treat.” There are a number of other useful tools for assessing study design and for quantifying effect size and cost-effectiveness. In general, these are the tools of epidemiology and biostatistics, and their discussion is beyond the scope of this chapter. A basic primer and glossary of terms is included in Table 227-2.
Box 227-1
Critical Appraisal of the Literature
Adapted from Sackett DL, Straus SE, Richardson WS et al. Evidence-based medicine: how to practice and teach EBM. London: Harcourt; 2000.

Systematic Reviews of Multiple Studies
The disadvantage of systematic reviews is that they are only as good as the studies they include and can only be interpreted if all the criteria just mentioned have been met. Unfortunately, there is considerable variability in the quality and comprehensiveness of available systematic reviews. Much of this dilemma stems from a lack of commonly accepted methodology for conducting and writing systematic reviews. For example, there are no standard exclusion criteria for studies in systematic reviews. Each author establishes the criteria, which the reader must assess to determine the quality and utility of the review to answer his clinical question. In addition, there is publication bias. Popular search techniques to identify studies are inherently limited by the fact that unpublished studies are unaccounted for in any review. Issues such as these have led authors to propose the development and maintenance of study registries where all RCTs are registered irrespective of their publication status.11 This would enable review of smaller studies and those studies published in journals not listed in cumulative Index Medicus, MEDLINE, and other popular databases in systematic reviews.
Related posts:


Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


