Category
Examples
Written and oral assessments
Multiple-choice questions (MCQ)
Matching and extended matching items
True-false and multiple true-false items
Fill-in-the-blank items
Long and short essay questions
Oral exams/vivas
Performance-based assessments
Long and short cases
Objective Structured Clinical Examinations (OSCE)
Simulation-based assessments
Clinical observation or work-based assessments
Mini-Clinical Evaluation Exercise (mini-CEX)
Direct Observation of Procedural Skills (DOPS)
360° evaluations/multisource feedback
Miscellaneous assessments
Patient surveys
Peer assessments
Self-assessments
Medical record audits
Chart-stimulated recall
Logbooks
Portfolios
Written and Oral Assessments
Written Assessments
Written tests have been in widespread use for nearly a century across all fields and stages of training; indeed, scores on written examinations often carry significant weight in selection decisions for entry into health professional training programs, and, as such, written tests can constitute high-stakes assessments. Written exams—whether in paper-and-pencil or computer-based formats—are the most common means used to assess cognitive or knowledge domains, and these generally consist of either selected–response/“closed question” (e.g., multiple-choice questions [MCQs] and various matching or true-false formats) or constructed–response/“open-ended question” (e.g., fill-in-the-blank and essay question) item formats. MCQs, in particular, have become the mainstay of most formal assessment programs in health professions education because they offer several advantages over other testing methods: MCQs can sample a very broad content range in a relatively short time; when contextualized with case vignettes, they permit assessment of both basic science and clinical knowledge acquisition and application; they are relatively easy and inexpensive to administer and can be machine scanned, allowing efficient and objective scoring; and a large body of research has demonstrated that these types of written tests have very strong measurement characteristics (i.e., scores are highly reliable and contribute to ample validity evidence) [46, pp. 30–49; 51–54].
Oral Assessments
Like written tests, oral examinations employ a stimulus–response format and chiefly assess acquisition and application of knowledge. The difference, obviously, is the form of the stimulus and response: As opposed to pencil-and-paper or computer test administration, in oral exams, the candidate verbally responds to questions posed by one or more examiners face to face (hence the alternate term “vivas,” so-called from the Latin viva voce, meaning “with the live voice”). In traditional oral exams, the clinical substrate is typically the (unobserved) interview and examination of an actual patient, after which the examinee verbally reports his or her findings and then a back-and-forth exchange of questions and answers ensues. Examiners ordinarily ask open-ended questions: Analogous to written constructed-response-type items, then, the aim is to assess more than just retention of facts but also ability to solve problems, make a logical argument in support of clinical decisions, and “think on one’s feet.” An advantage of oral exams over, say, essay questions is the possibility of dynamic interaction between examiner(s) and candidate, whereby additional queries can explore why an examinee answered earlier questions in a certain way. The flip side of that coin, however, is the possibility that biases can substantially affect ratings: Because the exam occurs face to face and is based on oral communication, factors such as examinee appearance and language fluency may impact scores. Oral exams face additional psychometric challenges in terms of (usually) limited case sampling/content specificity and, due to differences in examiner leniency/stringency, subjectivity in scoring. These issues pose threats to the reliability of scores and validity of judgments derived from oral assessment methods [46, pp. 27–29; 55, pp. 269–272; 56, p. 324; 57, pp. 673–674].
Performance-Based Assessments
Long Cases
Performance-based tests, in very general terms, all involve formal demonstration of what trainees can actually do, not just what they know. Traditional examples include the “long case,” whereby an examiner takes a student or candidate to the bedside of a real patient and requires that he or she shows how to take a history, perform a physical examination, and perhaps carry out some procedure or laboratory testing at the bedside. Because examinees usually answer questions about patient evaluation and discuss further diagnostic work-up and management, long cases also incorporate knowledge assessment (as in oral exams), but at least some of the evaluation includes rating the candidate’s performance of clinical skills at the bedside, not just the cognitive domains. Long (and/or several short) cases became the classic prototype for clinical examination largely because this type of patient encounter was viewed as highly authentic, but—because patients (and thus the conditions to be evaluated) are usually chosen from among those that happen to be available in the hospital or clinic on the day of the exam and because examiners with different areas of interest or expertise tend to ask examinees different types of questions—this methodology again suffers from serious limitations in terms of content specificity and lack of standardization [46, pp. 53–57; 55, pp. 269–281; 56, p. 324; 57, pp. 673–674].
Objective Structured Clinical Examination (OSCE)
Developed to avoid some of these psychometric problems, the Objective Structured Clinical Examination (OSCE) represents another type of performance-based assessment [58]: OSCEs most commonly consist of a “round-robin” of multiple short testing stations, in each of which examinees must demonstrate defined skills (optimally determined according to a blueprint that samples widely across a range of different content areas), while examiners rate their performance according to predetermined criteria using a standardized marking scheme. When interactions with a “patient” comprise the task(s) in a given station, this role may be portrayed by actual patients (but outside the real clinical context) or others (actors, health professionals, etc.) trained to play the part of a patient (simulated or standardized patients [SPs]; “programmed patients,” as originally described by Barrows and Abrahamson [6]). Whereas assessment programs in North America tend to use predominantly SPs, real patients are more commonly employed in Europe and elsewhere. One concern about the OSCE method has been its separation of clinical tasks into component parts: Typically examinees will perform a focused physical exam in one station, interpret a chest radiograph in the next, deliver the bad news of a cancer diagnosis in the following station, and so forth. A multiplicity of stations can increase the breadth of sampling (thereby improving generalizability), but this deconstruction of what, in reality, are complex clinical situations into simpler constituents appears artificial; although potentially appropriate for assessment of novice learners, this lack of authenticity threatens the validity of the OSCE method when evaluating the performance of experts, whom we expect to be able to deal with the complexity and nuance of real-life clinical encounters. An additional challenge is that OSCEs can be resource intensive to develop and implement. Nonetheless, especially with careful attention to exam design (including adequate number and duration of stations), rating instrument development, and examiner training, research has confirmed that the OSCE format circumvents many of the obstacles to reliable and valid measurement encountered with traditional methods such as the long case [46, pp. 58–64; 57, 59].
Simulation-Based Assessments
Besides their use in OSCEs, SPs and other medical simulators, such as task trainers and computer-enhanced mannequins, often represent the patient or clinical context in other performance-based tests [60, pp. 245–268; 61, pp. 179–200]. Rather than the multi-station format featuring brief simulated encounters, longer scenarios employing various simulations can form the basis for assessment of how individuals (or teams) behave during, say, an intraoperative emergency or mass casualty incident. We will elaborate more on these methods in later sections of this chapter, and specialty-specific chapters in the next section of the book will provide further details about uses of simulations for assessment in particular disciplines.
Clinical Observation or Work-Based Assessments
Clinical observational methods or work-based assessments have in common that the evaluations are conducted under real-world conditions in the places where health professionals ordinarily practice, that is, on the ambulance, in the emergency department or operating room or clinic exam room, on the hospital ward, etc. Provider interactions are with actual patients, rather than with SPs, and in authentic clinical environments. The idea here is to assess routine behaviors in the workplace (“in vivo,” if you will) as accurately as possible, rather than observing performance in artificial (“in vitro”) exam settings, such as the stations of an OSCE or even during long cases. Consequently, such observations must be conducted as unobtrusively as possible, lest healthcare providers (or even the patients themselves) behave differently because of the presence of the observer/rater. Work-based evaluation methods have only recently received increasing attention, largely due to growing calls from the public for better accountability of health professionals already in practice, some of whom have been found to be incompetent despite having “passed” other traditional assessment methods during their training [49, p. 8].
Mini-Clinical Evaluation Exercise (Mini-CEX)
Examples of work-based assessment methods include the Mini-Clinical Evaluation Exercise (mini-CEX), which features direct observation (usually by an attending physician, other supervisor, or faculty member) during an actual encounter of certain aspects of clinical skills (e.g., a focused history or physical exam), which are scored using behaviorally anchored rating scales. Because the assessment is brief (generally 15 minutes or so; hence the term “mini”), it can relatively easily be accomplished in the course of routine work (e.g., during daily ward rounds) without significant disruption or need for special scheduling; also, because this method permits impromptu evaluation that is not “staged,” the clinical encounter is likely to be more authentic and, without the opportunity to rehearse, trainees are more likely to behave as they would if not being observed. The idea is that multiple observations over time permit adequate sampling of a range of different clinical skills, and use of a standardized marking scheme by trained raters allows measurements to be fairly reliable across many observers [46, pp. 67–70; 62, pp. 196–199; 63, p. 339].
Direct Observation of Procedural Skills (DOPS)
Direct Observation of Procedural Skills (DOPS) is another method similar to the mini-CEX, this time with the domains of interest focused on practical procedures. Thus DOPS can assess aspects such as knowledge of indications for a given procedure, informed consent, and aseptic technique, in addition to technical ability to perform the procedure itself. Again, the observations are made during actual procedures carried out on real patients, with different competencies scored using a standardized instrument generally consisting of global rating scales. For this and most other work-based methods based on brief observations, strong measurement properties only accrue over time with multiple samples across a broad range of skills. One challenge, however, is that evaluation of such technical competencies usually requires that expert raters conduct the assessments [46, pp. 71–74].
360° Evaluations
By contrast, not all methods require that supervisory or other experienced staff carry out the observations. In fact, alternative and valuable perspectives can be gained by collecting data from others with whom a trainee interacts at work on a daily basis. Thus, peers, subordinate personnel (including students), nursing and ancillary healthcare providers, and even patients can provide evaluations of performance that are likely more accurate assessments of an individual’s true abilities and attitudes. A formal process of accumulating and triangulating observations by multiple persons in the trainee’s/practitioner’s sphere of influence comprises what is known as a 360° evaluation (also termed multisource feedback). Despite the fact that formal training seldom occurs on how to mark the rating instruments in these assessments, research has demonstrated acceptable reliability of data obtained via 360° evaluations, and, although aggregation of observations from multiple sources can be time and labor intensive, this process significantly decreases the likelihood that individual biases will impact ratings in a systematic way [46, pp. 82–85; 62, p. 199; 64].
Miscellaneous Assessments
Patient, Peer, and Self-Assessments
This “miscellaneous” category includes a variety of evaluation methods that don’t fit neatly under any one of the previous headings. In some cases, this is an issue of semantics related to how we define certain groupings. For example, we include in the classification of clinical observation or work-based assessments only those methodologies whereby data is collected on behaviors directly observed at the time of actual performance. On the other hand, if an assessment method yields information—albeit concerning real-world behaviors in the workplace—that is gathered indirectly or retrospectively, we list it here among other miscellaneous modalities. Therefore, as an example, patient satisfaction questionnaires completed immediately following a given clinic appointment that inquire about behaviors or attitudes the practitioner demonstrated during that visit would be included among clinical observation methods, such as part of 360° evaluations, whereas patient surveys conducted by phone or mail two weeks after a hospital admission—necessarily subject to recall and other potential biases—and based on impressions rather than observations would be grouped in the miscellaneous category. Similarly, peer assessments could be classified under more than one heading in our scheme. Self-assessments of performance, while they may have some utility for quality improvement purposes, are seldom used as a basis for making high-stakes decisions. Such ratings are extremely subjective: Personality traits such as self-confidence may influence evaluation of one’s own abilities, and research has demonstrated very poor correlation between self-assessments and judgments based on more objective measurements [63, pp. 338–339].
Medical Record Audits and Chart-Stimulated Recall
Chart audit as the basis for assessing what a clinician does in practice is another method of evaluation that we could classify in different ways: Clearly this is an indirect type of work-based assessment, whereby notes and other documentation in the written or electronic medical record provide evidence of what practitioners actually do in caring for their patients, but this can also represent a form of peer or self-assessment, depending on who conducts the audit. In any case, a significant challenge arises in choosing appropriate criteria to evaluate. Medical record review is also a relatively time- and labor-intensive assessment method, whose measurement properties are ultimately dependent on the quality (including completeness, legibility, and accuracy) of the original documentation [62, p. 197, 63, pp. 337–338; 65, pp. 60–67; 69–74].
Chart-stimulated recall is a related assessment method based on review of medical records, which was pioneered by the American Board of Emergency Medicine as part of its certification exams and later adopted by other organizations as a process for maintenance of certification. In this case, the charts of patients cared for by the candidate become the substrate for questioning during oral examination. Interviews focus retrospectively on a practitioner’s clinical judgment and decision-making, as reflected by the documentation in actual medical records, rather than by behaviors during a live patient encounter (as in traditional vivas or long cases). Chart-stimulated recall using just three to six medical records has demonstrated adequate measurement properties to be used in high-stakes testing, but this exam format is nonetheless expensive and time consuming to implement [55, p. 274, 65, pp. 67–74; 66, pp. 899, 905].
Logbooks and Portfolios
Logbooks represent another form of written record, usually employed to document number and types of patients/conditions seen or procedures performed by health professionals in the course of their training and/or practice. Historically, “quota” systems relied on documentation in logs—formerly paper booklets and nowadays frequently electronic files—of achievement of a defined target (for instance, number of central lines to be placed) to certify competence in a given area. These quotas were determined more often arbitrarily than based on evidence, and although some research suggests that quality of care is associated with higher practice volume [63, p. 337], other studies clearly show that experience alone (or “time in grade”) does not necessarily equate with expertise [67]. Additional challenges exist in terms of the accuracy of information recorded, irrespective of whether logbooks are self-maintained or externally administered. As a result, few high-stakes assessment systems rely on data derived from logbooks per se; instead, they are ordinarily used to monitor learners’ achievement of milestones and progression through a program and to evaluate the equivalence of educational experiences across multiple training sites [46, pp. 86–87; 63, p. 338].
The definition of portfolios as a method of assessment varies somewhat according to different sources: Whether the term is used in the sense of “a compilation of ‘best’ work” or “a purposeful collection of materials to demonstrate competence,” other professions (such as the fine arts) have employed this evaluation method far longer than the health professions [68, p. 86]. A distinguishing feature of portfolios versus other assessment modalities is the involvement of the evaluee in the choice of items to include; this affords a unique opportunity for self-assessment and reflection, as the individual typically provides a commentary on the significance and reasons for inclusion of various components of the portfolio. Many of the individual methods previously mentioned can become constituents of a portfolio. An advantage of this method, perhaps more than any other single “snapshot” assessment, is that it provides a record of progression over time. Although portfolio evaluations don’t readily lend themselves to traditional psychometric analysis, the accumulation of evidence and triangulation of data from multiple sources, although laborious in terms of time and effort, tend to minimize limitations of any one of the included assessment modalities. Nonetheless, significant challenges exist, including choice of content, outcomes to assess, and methods for scoring the portfolio overall [46, pp. 88–89; 68, 69, pp. 346–353; 70].
Rating Instruments and Scoring
We stated early on that this chapter’s scope would not encompass detailed discussion of various rating instruments, which can be used with practically all of the methods described above to measure or judge examinee performances during an assessment. Reports of the development and use of different checklists and rating scales abound, representing a veritable “alphabet soup” of instruments known by clever acronyms such as RIME (Reporter-Interpreter-Manager-Educator) [71], ANTS (Anesthetists’ Non-Technical Skills) [72], NOTSS (Non-Technical Skills for Surgeons) [72], SPLINTS (Scrub Practitioners’ List of Intraoperative Non-Technical Skills) [72], and others too numerous to count. Because development of such rating instruments should follow fairly rigorous procedures [73, 74], which can be time and labor intensive, we realize that many readers would like a resource that would enable them to locate quickly and use various previously reported checklists or rating forms. Such a listing, however, would quickly become outdated. Moreover, once again we caution against using rating instruments “off the shelf” with the claim that they have been “previously validated”: although the competency of interest may generally be the same, the process of validation is so critically dependent on context that the argument in support of decisions based on data derived from the same instrument must be repeated each time it is used under new/different circumstances (e.g., slightly different learner level, different number of raters, and different method of tallying points from the instrument). That said, the rigor with which validation needs to be carried out depends on the stakes of resulting assessment decisions, and tips are available for adapting existing rating instruments to maximize the strength of the validity argument [62, pp. 195–201]. Finally, it should be noted that we use rating instruments themselves only to capture observations and produce data; the manner in which we combine and utilize these data to derive scores and set standards, which we interpret to reach a final decision based on the assessment, is another subject beyond the scope of this chapter, but we refer the interested reader to several sources of information on this and related topics [75–77].
Multidimensional Framework for Assessment
In further developing a model for thinking about assessment and choosing among various methods, we suggest consideration of several dimensions of an evaluation system: (1) the outcomes that need to be assessed, (2) the levels of assessment that are most appropriate, (3) the developmental stage of those undergoing assessment, and (4) the overall context, especially the purpose(s), of the assessment (see Fig. 11.1). We will explore each of these in turn.
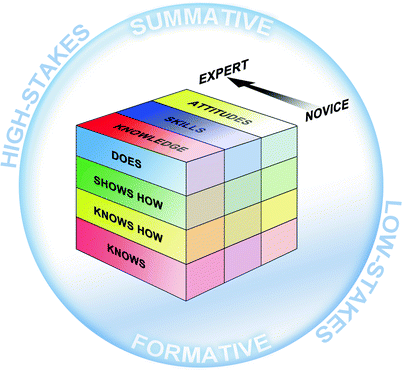
Fig. 11.1
Multidimensional framework for assessment
Outcomes for Assessment
In keeping with the outcomes-based educational paradigm that we discussed earlier, we must first delineate what competencies need to be assessed. We (the authors) are most familiar with the outcomes frameworks used in medical education in our home countries (the USA and Canada), and we will draw on these as examples for the discussion to follow. As previously mentioned, the ACGME outlines six general competencies: (1) patient care and procedural skills, (2) medical knowledge, (3) practice-based learning and improvement, (4) interpersonal and communication skills, (5) professionalism, and (6) systems-based practice [19]. While differing slightly in number, there is significant overlap between the six ACGME competencies and the outcomes expected of specialist physicians, which the CanMEDS framework describes in terms of seven roles that doctors must integrate: the central role is that of (1) medical expert, but physicians must also draw on the competencies included in the roles of (2) communicator, (3) collaborator, (4) manager, (5) health advocate, (6) scholar, and (7) professional to provide effective patient-centered care [18].
Accordingly, one way to choose among assessment modalities is to align various methods with the outcomes to be assessed. For example, when they elaborated the six general competencies (and a further number of “required skills” within each of these domains), the ACGME also provided a “Toolbox of Assessment Methods” with “suggested best methods for evaluation” of various outcomes [78]. This document lists thirteen methodologies—all of which were described in the corresponding section of this chapter (see Box)—and details strengths and limitations of each assessment technique. The metaphor of a “toolbox” is apt: a carpenter often has more than one tool at his disposal, but some are better suited than others for the task at hand. For example, he might be able to drive a nail into a piece of wood by striking it enough times with the handle of a screwdriver or the end of a heavy wrench, but this would likely require more time and energy than if he had used the purpose-built hammer. Similarly, while 360° evaluations are “a potentially applicable method” to evaluate “knowledge and application of basic sciences” (under the general competency of “medical knowledge”), it is fairly intuitive that MCQs and other written test formats are “the most desirable” to assess this outcomes area, owing to greater efficiency, robust measurement properties, etc. Table 11.2 provides an excerpt from the ACGME Toolbox showing suggested methods to evaluate various competencies, including some of the newer domains (“practice-based learning and improvement” and “systems-based practice”) that are not straightforward to understand conceptually and, therefore, have proven difficult to assess [79] (see Table 11.2).
Table 11.2
ACGME competencies and suggested best methods for assessment
Competency | Required skills | Suggested assessment methodsa |
|---|---|---|
Patient care and procedural skills | Caring and respectful behaviors | SPs, patient surveys (1) |
Interviewing | OSCE (1) | |
Informed decision-making | Chart-stimulated recall (1), oral exams (2) | |
Develop/carry out patient management plans | Chart-stimulated recall (1), simulations (2) | |
Preventive health services | Medical record audits (1), logbooks (2) | |
Performance of routine physical exam | SPs, OSCE (1) | |
Performance of medical procedures | Simulations (1) | |
Work within a team | 360° evaluations (1) | |
Medical knowledge | Investigatory and analytic thinking | Chart-stimulated recall, oral exams (1), simulations (2) |
Knowledge and application of basic sciences | MCQ written tests (1), simulations (2) | |
Practice-based learning and improvement | Analyze own practice for needed improvements | Portfolios (1), simulations (3) |
Use of evidence from scientific studies | Medical record audits, MCQ/oral exams (1) | |
Use of information technology | 360° evaluations (1) | |
Interpersonal and communication skills | Creation of therapeutic relationship with patients | SPs, OSCE, patient surveys (1) |
Listening skills | SPs, OSCE, patient surveys (1) | |
Professionalism | Respectful, altruistic | Patient surveys (1) |
Ethically sound practice | 360° evaluations (1), simulations (2) | |
Systems-based practice | Knowledge of practice and delivery systems | MCQ written tests (1) |
Practice cost-effective care | 360° evaluations (1) |
In similar fashion, when the Royal College of Physicians and Surgeons of Canada described several “key” as well as other “enabling” competencies within each of the CanMEDS roles, they provided an “Assessment Tools Handbook,” which lists important methods for assessing these competencies [80]. Just like the ACGME Toolbox, this document describes strengths and limitations of contemporary assessment techniques and ranks various tools according to how many of the outcomes within a given CanMEDS role they are appropriate to evaluate. For example, within this framework, written tests are deemed “well suited to assessing many of the [medical expert] role’s key competencies” but only “suited to assessing very specific competencies within the [communicator] role.” We could situate any of these sets of outcomes along one axis in our assessment model, but for illustrative purposes, we have distilled various core competencies into three categories that encompass all cognitive (“knowledge”), psychomotor (“skills”), and affective (“attitudes”) domains (see Fig. 11.1).
Levels of Assessment
The next dimension we should consider is the level of assessment within any of the specified areas of competence. George Miller offered an extremely useful model for thinking about the assessment of learners at four different levels: 1.Knows—recall of basic facts, principles, and theories. 2.Knows how—ability to apply knowledge to solve problems, make decisions, or describe procedures. 3.Shows how—demonstration of skills or hands-on performance of procedures in a controlled or supervised setting. 4.Does—actual behavior in clinical practice [42].
This framework is now very widely cited, likely because the description of and distinction between levels are highly intuitive and consistent with most healthcare educators’ experience: we all know trainees who “can talk the talk but can’t walk the walk.” Conceptualized as a pyramid, Miller’s model depicts knowledge as the base or foundation upon which more complex learning builds and without which all higher achievement is unattainable; for example, a doctor will be ill equipped to “know how” to make clinical decisions without a solid knowledge base. The same is true moving further up the levels of the pyramid: students cannot possibly “show how” if they don’t first “know how”, and so on. Conversely, factual knowledge is necessary but not sufficient to function as a competent clinician; ability to apply this knowledge to solve problems, for example, is also required. Similarly, it’s one thing to describe (“know how”) one would, say, differentiate among systolic murmurs, but it’s another thing altogether to actually perform a cardiac examination including various maneuvers (“show how”) to make the correct diagnosis based on detection and proper identification of auscultatory findings. Of course, we always wonder if our trainees perform their physical exams using textbook technique or carry out procedures observing scrupulous sterile precautions (as they usually do when we’re standing there with a clipboard and rating form in hand) when they’re on their own in the middle of the night, with no one looking over their shoulder. This—what a health professional “does” in actual practice, under real-life circumstances (not during a scenario in the simulation lab)—is the pinnacle of the pyramid, what we’re most interested to capture accurately with our assessments.
Although termed “Miller’s pyramid,” his original construct was in fact a (two-dimensional) triangle, which we have adapted to our multidimensional framework by depicting the levels of assessment along an axis perpendicular to the outcomes being assessed (see Fig. 11.1). Each (vertical) “slice” representing various areas of competence graphically intersects the four (horizontal) levels. Thus, we can envision a case example that focuses on the “skills” domain, wherein assessment is possible at any of Miller’s levels:
1.
Knows—a resident can identify relevant anatomic landmarks of the head and neck (written test with matching items), can list the contents of a central line kit (written test with MCQ items or fill in the blanks), and can explain the principles of physics underlying ultrasonography (written test with essay questions).
2.
Knows how—a resident can describe the detailed steps for ultrasound-guided central venous catheter (CVC) insertion into the internal jugular (IJ) vein (oral exam).
3.
Shows how—a resident can perform ultrasound-guided CVC insertion into the IJ on a mannequin (checklist marked by a trained rater observing the procedure in the simulation lab).
4.
Does—a resident performs unsupervised CVC insertion when on call in the intensive care unit (medical record audit, logbook review, or 360° evaluation including feedback from attendings, fellow residents, and nursing staff in the ICU).
Choice of the most appropriate evaluation methods (as in this example) should aim to achieve the closest possible alignment with the level of assessment required. It is no accident, therefore, that the various categories of assessment methods we presented earlier generally correspond to the different levels of Miller’s pyramid [46, pp. 22–24; 48, pp. 2–5]: written and oral assessments can efficiently measure outcomes at the “knows” and “knows how” levels, while performance-based assessments are most appropriate at the “shows how” level, and clinical observation or work-based and other miscellaneous assessment methods are best suited to evaluating what a clinician “does” in actual practice (see Table 11.3). Of course, because of the hierarchical nature of Miller’s scheme, methods that work for assessment at the upper levels can also be utilized to evaluate more fundamental competencies; for instance, 360° evaluations (directly) and chart-stimulated recall (indirectly) assess real-world behaviors, but they are also effective (albeit, perhaps, less efficient) methods to gauge acquisition and application of knowledge. In addition, the interaction between these two dimensions—outcomes of interest and levels of assessment—describes a smaller set of evaluation tools that are best suited to the task. For this reason, although multiple techniques might have applications for assessment of a given ACGME competency, the Toolbox suggests relatively few as “the most desirable” methods of choice [78].
Table 11.3




Levels of assessment and corresponding assessment methods
Related posts:






Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
